Editors’ Highlights are summaries of recent papers by AGU’s journal editors.
Source: Journal of Geophysical Research: Earth Surface
Permafrost beneath Arctic roads is warming and becoming less stable, creating growing risks for northern infrastructure. Yet predicting how frozen ground will evolve remains difficult because subsurface conditions vary sharply over short distances, observations are sparse, and conventional process-based models are not easy to update as new field data arrive.
Source: Journal of Geophysical Research: Earth Surface
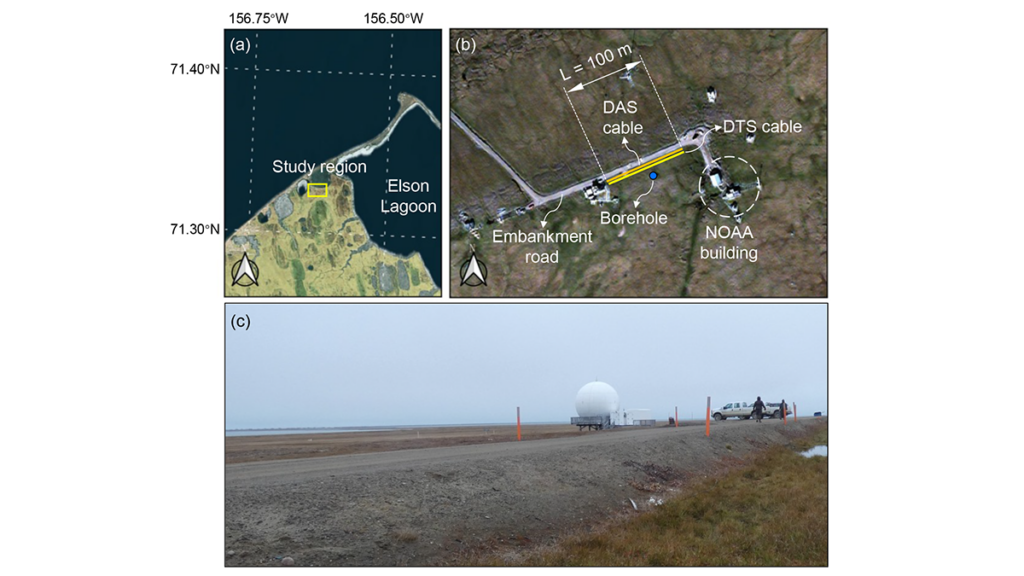
Permafrost beneath Arctic roads is warming and becoming less stable, creating growing risks for northern infrastructure. Yet predicting how frozen ground will evolve remains difficult because subsurface conditions vary sharply over short distances, observations are sparse, and conventional process-based models are not easy to update as new field data arrive. In a new study, Gou et al. [2026] address that challenge at an embankment road in Utqiaġvik, Alaska, using fiber-optic temperature measurements collected along a 100-meter transect to track how shallow ground conditions change through time. Rather than treating monitoring and modeling as separate tasks, the authors link them in a framework designed to evolve with the physical system itself.
What stands out here is not simply the use of machine learning, but the way the authors build a physics-informed digital twin for permafrost under infrastructure. Their framework embeds a neural network within a heat-transfer solver, so the governing physics remain central while the model can still update uncertain soil properties as new observations arrive. This study moves beyond black-box prediction toward an interpretable, updateable system that can reconstruct subsurface temperature fields, infer thermodynamic properties such as unfrozen water content and thermal conductivity, and then test those inferences against independent DAS data, borehole temperatures, and laboratory measurements. This makes the work more than a site-specific modeling exercise; it offers a credible pathway toward near-real-time permafrost forecasting and infrastructure monitoring in a rapidly warming Arctic.
Framework of the proposed digital twin model. The neural network (NN) takes soil temperature at each lateral position as input and outputs six unknown parameters that vary laterally with distance. These parameters are embedded in the heat‐transfer equation through constitutive relationships, and the resulting system is solved using a finite difference method (FDM). The difference between predicted and observed temperatures is computed and defined as “loss,” and the loss gradients are backpropagated to update the NN parameters. Credit: Gou et al. [2026], Figure 2
Citation: Gou, L., Xiao, M., Zhu, T., Martin, E. R., Wang, Z., Rocha dos Santos, G., et al. (2026). Physics-informed digital twin for predicting permafrost thermodynamic characteristics under an embankment road in Utqiaġvik, Alaska. Journal of Geophysical Research: Earth Surface, 131, e2025JF008787. https://doi.org/10.1029/2025JF008787
Source: Geophysical Research Letters
Real-time hydrologic forecasting predicts river level and flooding inundation by combining continuously updated rainfall measurements, river gauge readings, and weather forecasts. Most of these flood forecasting systems depend on human interpretation and adjustments, or a “forecasters-in-the-loop” approach, which pairs computer models with a human expert on flood dynamics and local conditions. In contrast, in a “forecasters-over-the-loop” system, humans
Real-time hydrologic forecasting predicts river level and flooding inundation by combining continuously updated rainfall measurements, river gauge readings, and weather forecasts. Most of these flood forecasting systems depend on human interpretation and adjustments, or a “forecasters-in-the-loop” approach, which pairs computer models with a human expert on flood dynamics and local conditions. In contrast, in a “forecasters-over-the-loop” system, humans supervise automated forecasts and intervene only if necessary.
Recently, artificial intelligence (AI) and machine learning (ML) have become more integrated into flood prediction, and many of these systems are faster at processing large datasets and learning complex patterns from historical records than traditional models alone. But these new technologies also come with limitations—AI and ML require extensive data and may struggle to capture extreme, rare events.
Even though ML and AI are often touted as the future of flood forecasting, most studies have tested this technology against models that provide historical simulations, not the real-time operational systems that would be used during a flood. These simplified models may lack local details or are tested at daily rather than hourly resolution. Their effectiveness may be overestimated.
Tran et al. produced the first study comparing the performance of ML models to an actual flood forecasting system used at the California Nevada River Forecast Center (CNRFC) that uses professional forecasters and traditional hydrologic models. The study suggests that a forecasters-in-the-loop approach outperforms the ML models in several key ways, including streamflow predictions and flood event detection, because forecasters can recognize model errors and account for poor input data—actions models cannot take on their own.
The researchers used data gathered from CNRFC river stage forecasts across 50 California and Nevada locations between 2012 and 2022 and river condition lead times from 1 to 96 hours. Compared to the ML models, the Community Hydrologic Prediction System used at CNRFC generally performed better at predicting stream flow and flood peaks, especially with longer lead times. Though the ML models could perform better at very short lead times, their accuracy declined quickly. Though automated forecasting options may seem promising, they are not yet a suitable replacement for human expertise when it comes to protecting lives and livelihoods from damaging floods, the researchers say. (Geophysical Research Letters,https://doi.org/10.1029/2025GL118317, 2026)
Citation: Owen. R. (2026), Keeping humans in the loop improves flood forecasting, Eos, 107, https://doi.org/10.1029/2026EO260161. Published on 19 May 2026.
Source: Earth’s Future
Coastal landscapes are constantly being reshaped by natural forces, and as climate change causes more frequent storms and sea level rise, that change will only intensify. Because these areas are densely populated with homes, tourist destinations, and industries, understanding how and where the coast will change is a pressing issue. However, reliable predictions that lead to actionable knowledge are rare.
Lentz et al. describe the state of knowledge regarding coastal
Coastal landscapes are constantly being reshaped by natural forces, and as climate change causes more frequent storms and sea level rise, that change will only intensify. Because these areas are densely populated with homes, tourist destinations, and industries, understanding how and where the coast will change is a pressing issue. However, reliable predictions that lead to actionable knowledge are rare.
Lentz et al. describe the state of knowledge regarding coastal evolution, highlight gaps in scientists’ understanding, and describe opportunities for integrating information from various models, data sources, and end users.
Current coastal evolution predictions are often focused on too specific a location and are therefore hard to generalize or analyze too large a region and therefore lack detail, the authors say. In addition, it’s challenging for researchers to link the effects of acute events, such as storms, with long-term trends like sea level rise.
Improving these simulations will likely require combining many different types of models, including physics-based numerical models, models based on empirical measurements, and statistical models that include machine learning. To fully understand potential changes, the authors note that it is also essential to consider both coastal processes and human actions.
The researchers recommend several ways to improve consistency and collaboration in the field of coastal change forecasting. First, standardizing approaches and outcomes would make it easier to produce national-scale predictions. Right now, the variety of tools used across different locations makes it difficult for scientists to compare results and communicate effectively. They also emphasize the need for using coordinated research approaches. Stronger transdisciplinary collaboration, accompanied by essential training and support, would also enable scientists to make better predictions, the researchers say.
Comparing predictions to real-world observations of coastal landscape change could also help untangle this multifaceted challenge. By studying how coastlines have already changed, researchers can validate models and choose those that are performing best. Such comparisons require datasets that adequately capture coastal landscape change across both time and space. Remote sensing data and the use of artificial intelligence (AI) for data processing may help provide these improved datasets, the researchers suggest.
Engaging end users during the project planning process is also helpful because only end users truly know what kind of information they need to adapt to landscape change. Knowing how to engage end users can be difficult for physical scientists, but various tools and specialized personnel exist who can help coordinate these interactions, the authors say. (Earth’s Future, https://doi.org/10.1029/2024EF005833, 2026)
Editors’ Highlights are summaries of recent papers by AGU’s journal editors.
Source: Journal of Advances in Modeling Earth Systems
The purpose of atmospheric data assimilation is to obtain a 3-dimensional gridded representation of the fields of the atmospheric state variables (temperature, wind, pressure, etc.) for a specific time based on atmospheric observations. The product of data assimilation, called analysis, can be used to prepare weather maps and to start model-based weather forec
Source: Journal of Advances in Modeling Earth Systems
The purpose of atmospheric data assimilation is to obtain a 3-dimensional gridded representation of the fields of the atmospheric state variables (temperature, wind, pressure, etc.) for a specific time based on atmospheric observations. The product of data assimilation, called analysis, can be used to prepare weather maps and to start model-based weather forecasts. Analyses collected over a long period of time can also be used for research and to monitor variability and changes in the climate.
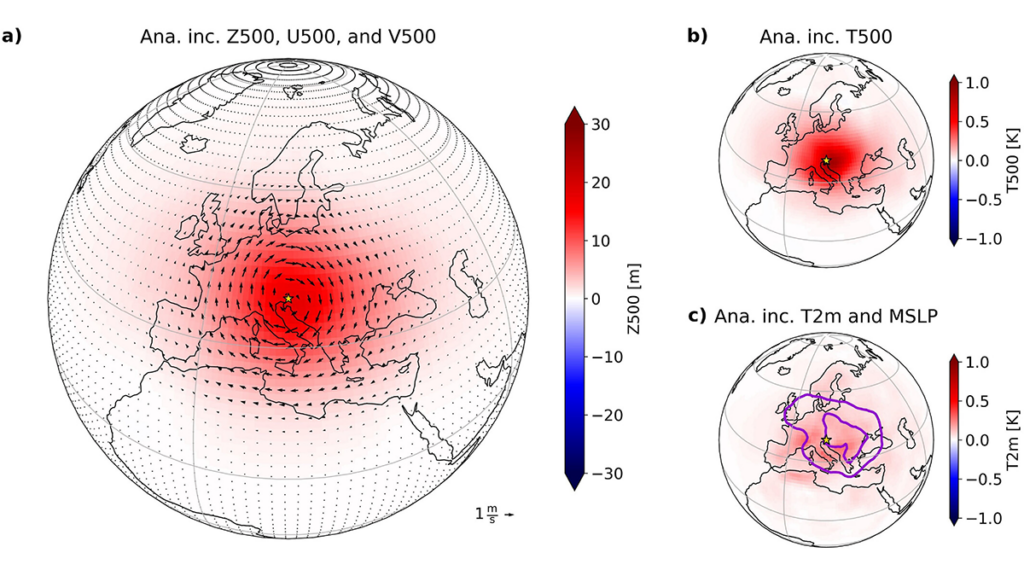
The main challenges of data assimilation are that observations are not collocated with the grid-points of the analysis, and most observations do not observe the variables of interest directly and have errors. For example, satellite-based observations, which form the bulk of the operationally assimilated observations, measure the intensity of electro-magnetic waves at the top of the atmosphere; a physical quantity that depends on the atmospheric state in highly complicated ways. The background-error covariance matrix is a key component of a data assimilation system, responsible for spreading information from observations to the unobserved locations and state variables. A good estimate of this matrix is essential to produce analyses in which the fields of the state variables are realistic and consistent with each other. Obtaining such an estimate is particularly challenging for tropical locations, where physics-based knowledge does not lead to a straightforward practical formulation.
In a new study, Melinc et al. [2026] propose a novel machine learning-based (ML-based) approach to define a background-error matrix that is equally effective in the midlatitudes and tropics. This approach takes advantage of the power of ML to learn quantitative relationships between different state variables at different locations-relationships that are either not known, or cannot be easily used for the formulation of a background-error matrix based on physics-based knowledge.
Citation: Melinc, B., Perkan, U., & Zaplotnik, Ž. (2026). A unified neural background-error covariance model for midlatitude and tropical atmospheric data assimilation. Journal of Advances in Modeling Earth Systems, 18, e2025MS005360. https://doi.org/10.1029/2025MS005360
Editors’ Vox is a blog from AGU’s Publications Department.
Ensuring the sustainability of water resources and ecosystems in a changing world requires a thorough understanding of how water moves through Earth’s Critical Zone, a dynamic interface where air, water, soil, plants, and rocks interact. Researchers can track and model this movement of water using naturally occurring markers or “tracers.”
A recent article in Reviews of Geophysics explores the latest advancements in tracer-aided mi
Ensuring the sustainability of water resources and ecosystems in a changing world requires a thorough understanding of how water moves through Earth’s Critical Zone, a dynamic interface where air, water, soil, plants, and rocks interact. Researchers can track and model this movement of water using naturally occurring markers or “tracers.”
A recent article in Reviews of Geophysics explores the latest advancements in tracer-aided mixing models and how they can help us to better understand the Critical Zone. Here, we asked the authors to give an overview of the Critical Zone, how tracer-aided mixing modeling works, and future directions for research.
What is the Critical Zone (CZ)?
The Critical Zone is Earth’s “living skin”—the dynamic layer where the atmosphere, hydrosphere, biosphere, and lithosphere interact. It stretches from the top of the vegetation canopy and, in cold regions, from the surface of snowpacks and glaciers, down through soils and into the deeper aquifers. It encompasses lakes, streams, and wetlands at the surface, and extends beyond the soil layer to underlying groundwater aquifers. It is where rainfall, snowmelt and glacier melt become soil moisture, where plants take up water and return it to the atmosphere, where aquifers get recharged, and where streamflow is generated. In short, the Critical Zone is where most processes that sustain terrestrial life and freshwater resources unfold.
Why is it important to understand how water moves through the Critical Zone?
Virtually every freshwater resource we rely on (e.g., drinking water, irrigation) passes through the Critical Zone.
Virtually every freshwater resource we rely on (e.g., drinking water, irrigation) passes through the Critical Zone at some point. Global warming, land-use changes, and intensifying water demand emerging from rapid urbanization and changes in agriculture are reshaping how water is stored and released within the Critical Zone, often in ways we cannot yet predict. Understanding how much water is stored within the Critical Zone, how this water is both recharged from rainfall and snowmelt and eventually discharged into streams, and the timescale of these dynamic processes is essential for protecting ecosystems, safeguarding water supplies, and adapting to a changing climate.
How would you explain a tracer-aided mixing model to a non-specialist?
Imagine mixing a glass of orange juice with a glass of apple juice, and trying afterwards to work out how much of each went into the glass. If the juices had distinctive “fingerprints” (imagine its color, sugar content, or a specific chemical) and these fingerprints primarily changed because of the mixing of these two juices, you can then measure the fingerprint in the final mixture and back-calculate the proportion of its distinct sources.
Tracer-aided mixing models work in a similar way but can track the entire water cycle. Different water sources (e.g., rainfall, snowmelt, glacier melt, soil water, groundwater) can have distinct “fingerprints” in a naturally occurring tracer, such as stable isotopes of water or specific dissolved elements. By measuring these fingerprints in the streamwater or groundwater and in its potential sources for example, hydrologists can estimate how much each source contributed to the streamwater or groundwater.
Conceptual model of the different components of the Critical Zone. “Gw” stands for groundwater. Credit: Popp et al. [2025], Figure 2
What are some of the most significant and exciting recent advances in tracer-aided mixing models?
Classical mixing models relied on demanding assumptions: that all water sources can be identified and sampled, and that their signatures were distinct and constant in time. Much of the recent progress has been about relaxing these assumptions.
Bayesian approaches now estimate full probability distributions and provide a more realistic picture of uncertainty. Methods like Convex Hull End-Member Mixing Analysis (CHEMMA) use machine learning to infer the distinct sources directly from data, while ensemble hydrograph separation exploits tracer fluctuations over time, thereby making un-mixing feasible even when multiple sources have overlapping signatures. Perhaps the most conceptually novel advance is end-member splitting, which flips the question from “where does streamflow come from?” to “where does precipitation go?”
Alongside these modeling advances, there have been immense advances in how tracers are measured. Portable laser and mass spectrometers now enable high-frequency, in-situ tracer measurements which allows us to capture critical hydrological events such as storms and snowmelt in near-real time.
What are stable water isotope tracers and what are their advantages?
Stable water isotopes are naturally occurring non-radioactive atoms of hydrogen and oxygen that make up a water molecule but have slightly different molecular masses. The two stable isotopes widely used in hydrology are 2H (deuterium) and 18O (oxygen-18). Because these isotopes are part of the water molecule itself, they directly travel with the water molecule. Their key advantages are: (1) they are conservative, meaning they do not react chemically as water moves through soils and aquifers, and (2) they carry distinct signatures resulting from climatic variables such as air temperature.
These properties make stable water isotopes the most versatile and widely used tracer in Critical Zone hydrology.
Consequently, in the European Alps, winter precipitation has a different isotopic signature than summer precipitation because winters are cooler than summers. Other hydrological processes such as evaporation and sublimation leave a recognizable fingerprint on the remaining water, thereby allowing us to estimate how much evaporation or sublimation occurred. Stable water isotopes can be measured in essentially every water compartment, from atmospheric vapor and precipitation to snowpack, plant xylem, soil water, streams, and groundwater. Together, these properties make stable water isotopes the most versatile and widely used tracer in Critical Zone hydrology.
What are the current limitations of tracer-aided mixing models?
Despite their power, mixing models still face many constraints. End-member signatures vary in space and time, are sometimes too similar to distinguish, and some sources may be overlooked entirely. Non-conservative tracers such as nitrate or sulfate can react with their environment along their journey, thereby biasing results if these reactions are not explicitly accounted for.
Sampling is another major bottleneck. Capturing the spatial heterogeneity of soils, snowpacks, and groundwater requires a lot of measurements that are often logistically or financially prohibitive, especially in remote regions. Many of the newer, more powerful tracers such as noble gases or stable isotopes of trace elements, can only be analyzed by a handful of specialized laboratories. As a result, global coverage remains highly uneven, with key regions such as the Arctic and the global South still under-sampled.
What are some of the major unsolved questions and where is more research needed?
There are several fronts where more research is needed. Source signatures are not static, and methods that explicitly capture their variability in time are still underdeveloped. Embedding tracers within global Earth System Models would, in theory, enable more accurate assessment of hydrological partitioning e.g., how rainfall, snowmelt, and glacier melt are split between sublimation, evapotranspiration, groundwater, and streamflow. These will directly inform more robust climate projections, but this remains technically demanding.
Expanding data coverage in under-sampled regions is critical, and citizen science and low-cost sensors may help. Machine learning is a promising approach for uncovering non-linear relationships and gap-filling sparse datasets, but requires training data that often do not yet exist. Greater interdisciplinary integration, e.g., combining tracers with remote sensing, ecological indicators, and biogeochemical data, could yield a more holistic view of the Critical Zone. Finally, the field would benefit from shared protocols and open data practices to enhance progress.
Editor’s Note: It is the policy of AGU Publications to invite the authors of articles published in Reviews of Geophysics to write a summary for Eos Editors’ Vox.
Citation: Popp, A. L., and H. Beria (2026), Tracing water’s hidden journey through the Earth’s living skin, Eos, 107, https://doi.org/10.1029/2026EO265019. Published on 13 May 2026.
This article does not represent the opinion of AGU, Eos, or any of its affiliates. It is solely the opinion of the author(s).
Solar activity affecting Earth and its planetary neighbors encompasses a wide range of phenomena, from the steady solar wind and the interplanetary magnetic field to extreme events like solar flares, coronal mass ejections (CMEs), and solar energetic particle (SEP) events. These space weather phenomena interact in complex ways with planetary magnetospheres and atmospheres. On Earth, we see the results in the dancing lights of stunning auroras and in less frequent but sometimes severe disruption
Solar activity affecting Earth and its planetary neighbors encompasses a wide range of phenomena, from the steady solar wind and the interplanetary magnetic field to extreme events like solar flares, coronal mass ejections (CMEs), and solar energetic particle (SEP) events. These space weather phenomena interact in complex ways with planetary magnetospheres and atmospheres. On Earth, we see the results in the dancing lights of stunning auroras and in less frequent but sometimes severe disruptions to telecommunications, navigation, and energy infrastructure.
Forecasting conditions throughout the heliosphere (the region influenced by the solar wind), understanding the variety of Sun-Earth interactions, and predicting arrivals of space weather events—both benign and potentially hazardous—are a grand challenge.
The Sun-Earth challenge requires tracking and predicting conditions—from routine and quiet to rare and extreme—across tens of millions of kilometers of interplanetary space.
Solar flares emit electromagnetic radiation that spreads in all directions. In contrast, the propagation of CMEs and SEP events depends on their source location on the Sun and on the heliospheric magnetic field, which is carried outward by the solar wind. The impacts these events have on magnetosphere systems further vary depending on particle energies and intensities in SEPs and on particle speeds and the magnetic field orientation in CMEs. The Sun-Earth challenge thus requires tracking and predicting conditions—from routine and quiet to rare and extreme—across tens of millions of kilometers of interplanetary space.
This tracking and prediction is powered by petabyte-scale datasets from solar observatories and spacecraft measurements that provide rich observational archives. Researchers use these data to deduce physically meaningful quantities describing the heliosphere and to identify patterns to distinguish quiet from active conditions. The resulting insights not only answer fundamental science questions but also provide critical prediction time frames needed by space weather forecasters.
Even with all these data, the enormity of space between the Sun and Earth presents a major obstacle to our predictive capabilities. Another obstacle is that the data are obtained by different instruments operating at different locations and times. These factors combine to create a unique data sparsity challenge that complicates large-scale analysis.
These fundamental issues—the massive yet still insufficient supply of data available, the extreme differences in the scales of the processes we must illuminate, and the need for actionable predictions—suggest opportunities for artificial intelligence (AI) and machine learning (ML) to complement traditional physics-based analytical approaches [Camporeale, 2019]. In a series of workshops—insights from which inform the discussion below—scientists explored such opportunities and how they can advance heliophysics research and operational space weather forecasting.
The Need for Space Weather Forecasting
Space weather events can have significant impacts on infrastructure and humans. They can disrupt satellite operations (e.g., by enhancing atmospheric drag on satellites), damage electronics in space, interfere with radio communications and GPS, and even affect power grids (e.g., through geomagnetically induced currents) during the most severe events. They can also pose risks to people, especially astronauts beyond the protection of Earth’s atmosphere and airline crews and passengers on long-distance polar flights, during which exposure to energetic particles is elevated. Forecasting offers a first line of defense in preparing for or preventing damaging and hazardous effects of space weather.
In assessing major CMEs, forecasters consider whether and when events will reach Earth and whether they will trigger geomagnetic storms and substorms. For SEP events, predictions must include arrival times, peak intensities, durations, and energy characteristics.
Predicting extreme space weather phenomena is vital, but equally important is forecasting periods when no significant activity is expected, which is critical information for satellite operators and other stakeholders. Making such predictions requires understanding physics spanning 8 orders of magnitude in space and time, from subsecond processes in Earth’s magnetic environment to multiday solar eruptions propagating across the 150 million kilometers between the Sun and Earth (Figure 1) and long-term interactions at scales associated with the 11-year solar cycle.
Fig 1. Length scales and Sun-to-Earth transit times vary greatly for different types of space weather (SW), including solar flares, solar energetic particle (SEP) events, coronal mass ejections (CMEs), and interplanetary coronal mass ejections (ICMEs). High-speed particles are the first to arrive, usually within minutes of a flare, whereas CMEs arrive in 2–4 days. Credit: Georgoulis et al. [2026], CC BY-NC-ND 4.0
In addition to operational forecasting, these challenges are fundamental in heliophysics research. Such research includes work to reveal how the Sun generates its magnetic field, how solar wind accelerates and evolves, how planetary magnetospheres respond to external forcing, how particles are accelerated, and how energy transfers across multiple scales and regimes.
Unique Challenges in Heliophysics
Modern AI and ML algorithms excel at analyzing well-curated, extensive datasets that include millions of training examples. For example, AI-aided terrestrial weather forecasting relying on continuous, high-resolution coverage from thousands of ground stations, weather balloons, and satellites has advanced dramatically in recent years.
Fewer than a dozen spacecraft monitor Earth’s magnetosphere, a region spanning tens of Earth radii. Solar wind observations are even sparser.
Heliophysics, however, presents a unique and somewhat opposite scenario. Fewer than a dozen spacecraft monitor Earth’s magnetosphere, a region spanning tens of Earth radii (about 6,371 kilometers). Solar wind observations are even sparser, with just a handful of monitors scattered across the space between the Sun and Earth. This fundamental scarcity poses a challenge for data-driven approaches, which typically depend on abundant observations that are well distributed in space and time to produce trustworthy (i.e., generalizable and reproducible) models.
Data sparsity is further compounded by the relative rarity of intense space weather phenomena such as CMEs, major geomagnetic storms, and extreme substorms, which occur only a few times per solar cycle. Most heliophysical observations capture quiet, low-activity conditions when the solar wind is steady and magnetospheres are calm. Standard ML approaches trained on such imbalanced datasets may achieve high statistical accuracy by simply predicting a “nothing-will-happen” outcome but completely fail when extreme events occur.
Although solar eruptions and geomagnetic storms are relatively rare, they exhibit recurring patterns and consistency in their physical drivers. This regularity suggests that historical observations, when properly clustered and analyzed, can be used to enhance prediction capabilities. The challenge therefore lies in extracting meaningful patterns from sparse measurements of rare events while avoiding models that work well for average conditions but fail when they matter most [Chu et al., 2025].
AI Solutions for Data Sparsity
Heliophysics research employs clever approaches to extract maximum information from the limited available observations. One strategy is to mine multidecade observational records from various satellites and to match and group together measurements collected at times with similar solar wind and geomagnetic activity conditions.
Another, more universal approach is to embed fundamental physical laws directly into ML models through physics-informed neural networks [Raissi et al., 2019], ensuring that predictions respect physical reality even when training data are limited. Data assimilation techniques used in weather forecasting similarly blend sparse observations with physics-based simulations and update models as new measurements arrive.
This animated model shows Earth’s magnetosphere during a powerful May 2024 geomagnetic storm that involved strong solar flares and multiple CMEs. The visualization uses the Multiscale Atmosphere-Geospace Environment (MAGE) model from the Johns Hopkins Applied Physics Laboratory to depict wind rushing toward Earth and disturbing its magnetic field (orange and purple lines). The green cloud represents electric field current intensity; the blue squiggles are tracers of solar wind velocities. Credit: NASA Scientific Visualization Studio and NASA DRIVE Science Center for Geospace Storms
These methods converge on a common theme: building gray box models (so named because they’re less opaque than black box models) that are data driven but grounded in physically real constraints. For data-starved applications, hybrid approaches can outperform purely data-driven or purely physics-based methods [Liu et al., 2025].
Satellite instruments are generating increasingly large solar wind datasets. However, the variables obtained (e.g., solar wind speed and pressure) are highly intercorrelated [Borovsky, 2018], making it difficult to identify which ones truly drive magnetospheric responses. New algorithms are helping to distill datasets without losing critical scientific information [e.g., Camporeale, 2025]. Meanwhile, advanced statistical and ML methods can cut through dataset complexity by reducing dimensionality, identifying causal relationships among variables, and providing clues about dominant drivers.
For instance, information theory provides tools to detect dependencies in complex systems, establish causality, and rank variables that most effectively predict space weather outcomes [Wing et al., 2022]. Such techniques can be paired with other “explainable” tools, such as SHAP (SHapley Additive exPlanations) values, a method inspired by game theory, to pinpoint physical variables (e.g., solar wind speed or magnetic orientation) that drive a prediction [Ma et al., 2023].
Distilling datasets and improving model interpretability help make ML more practical and more scientifically trustworthy and its predictions more robust. But fully trusting ML models in operational environments requires rigorous validation and uncertainty quantification. These models must not only make predictions but also indicate their confidence levels for operational decisionmaking.
When a model forecasts a major geomagnetic storm, operators need to know whether that prediction carries 60% or 95% confidence, for example.
When a model forecasts a major geomagnetic storm, operators need to know whether that prediction carries 60% or 95% confidence, for example. Ensemble approaches, in which multiple models provide a range of outcomes, help quantify this uncertainty, while using standardized, well-documented datasets enables fair model intercomparisons.
The research community is developing ML-ready benchmark datasets with consistent formatting and clear metadata to establish such validation procedures [e.g., Angryk et al., 2020]. These resources allow researchers to test new algorithms against common baselines, accelerating progress while ensuring that advances are robust and reproducible rather than artifacts of specific data processing choices.
Notably, one domain in heliophysics that is not affected by severe data sparsity is solar imaging. Decades of continuous, high-resolution observations from the Solar Dynamics Observatory (SDO), which delivers 1.5 terabytes of data every day, have created enormous data archives. Because the Sun drives space weather throughout the heliosphere, these datasets offer an ideal opportunity for use in foundation models, large-scale ML systems trained to learn comprehensive internal representations that can then be easily adapted to specific scientific tasks with minimal additional training.
Surya, a foundation model designed to construct a digital representation of the Sun, represents one such effort. It is still in early development and has yet to be validated, but this approach illustrates how data-rich domains can be leveraged with modern AI techniques to create tools that broadly benefit heliophysics research and space weather forecasting.
Advancing Research and Operational Forecasting Together
In addition to the needs for data and model development and validation, applying AI to address the challenges of heliophysics requires sustained, multidisciplinary collaborations. Fostering those collaborations has been the focus of a series of workshops, with the most recent being 2025’s Machine Learning, Data Mining and Data Assimilation in Geospace (LMAG25) meeting at the Johns Hopkins University Applied Physics Laboratory. The workshops have brought together heliophysicists, machine learning experts, data scientists, and specialists from weather forecasting and applied mathematics to exchange knowledge and establish community standards.
Space weather forecasters need models that are accurate and interpretable and that provide not just statistical metrics but also actionable predictions.
The LMAG forums also serve as gathering spaces for scientists to validate models against diverse datasets, compare physics-based and data-driven approaches, develop performance benchmarks, and discuss how to bridge research and operational requirements. Space weather forecasters need models that are accurate and interpretable and that provide not just statistical metrics but also actionable predictions with known limitations and reliability. Of course, researchers also benefit. These conversations allow them to gain insight into operational constraints that shape how modeling approaches become practical in real-world settings.
LMAG and similar initiatives facilitate direct exchanges among adjacent communities, including by making meeting presentations openly available. These efforts are helping translate cutting-edge AI and ML techniques into practical tools that help protect critical infrastructure and human well-being. They are also deepening our understanding of how the Sun shapes space weather throughout the solar system and its effects—both mundane and major—on Earth.
Borovsky, J. E. (2018), The spatial structure of the oncoming solar wind at Earth and the shortcomings of a solar-wind monitor at L1, J. Atmos. Sol. Terr. Phys., 177, 2–11, https://doi.org/10.1016/j.jastp.2017.03.014.
Camporeale, E. (2019), The challenge of machine learning in space weather: Nowcasting and forecasting, Space Weather, 17(8), 1,166–1,207, https://doi.org/10.1029/2018SW002061.
Chu, X., et al. (2025), Imbalanced Regression Artificial Neural Network Model for Auroral Electrojet Indices (IRANNA): Can we predict strong events?, Space Weather, 23(5), e2024SW004236, https://doi.org/10.1029/2024SW004236.
Georgoulis, M. K., et al. (2026), Prediction of solar energetic events impacting space weather conditions, Adv. Space Res., in press, https://doi.org/10.1016/j.asr.2024.02.030.
Liu, Y., et al. (2025), Data-driven modeling of electrostatic turbulence by physics-informed Fourier neural operator, Mach. Learn. Sci. Technol., 6(4), 045050, https://doi.org/10.1088/2632-2153/ae19cd.
Ma, D., et al. (2023), Opening the black box of the radiation belt machine learning model, Space Weather, 21(4), e2022SW003339, https://doi.org/10.1029/2022SW003339.
Raissi, M., P. Perdikaris, and G. E. Karniadakis (2019), Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378, 686–707, https://doi.org/10.1016/j.jcp.2018.10.045.
Stephens, G. K., et al. (2019), Global empirical picture of magnetospheric substorms inferred from multimission magnetometer data, J. Geophys. Res. Space Phys., 124(2), 1,085–1,110, https://doi.org/10.1029/2018JA025843.
Wing, S., et al. (2022), Modeling radiation belt electrons with information theory informed neural networks, Space Weather, 20(8), e2022SW003090, https://doi.org/10.1029/2022SW003090.
Author Information
Savvas Raptis (savvas.raptis@jhuapl.edu), Manolis K. Georgoulis, Mikhail Sitnov, Anthony Sciola, and Simon Wing, Johns Hopkins University Applied Physics Laboratory, Laurel, Md.
Citation: Raptis, S., M. K. Georgoulis, M. Sitnov, A. Sciola, and S. Wing (2026), Vast space, sparse data: An AI answer to twin space weather challenges, Eos, 107, https://doi.org/10.1029/2026EO260188. Published on 11 June 2026.
Every chip fabricated in a semiconductor plant needs ultrapure water. Most nuclear reactors need water as a coolant and neutron moderator. Every artificial intelligence (AI) data center drinks between 1 million and 5 million gallons of water a day, with thirst often peaking during drought.
Water runs through every technology priority the United States has named, yet the word does not appear once in “Launching the Genesis Mission,” an executive order (EO) released in November 2025. As describ
Every chip fabricated in a semiconductor plant needs ultrapure water. Most nuclear reactors need water as a coolant and neutron moderator. Every artificial intelligence (AI) data center drinks between 1 million and 5 million gallons of water a day, with thirst often peaking during drought.
Water runs through every technology priority the United States has named, yet the word does not appear once in “Launching the Genesis Mission,” an executive order (EO) released in November 2025. As described in the EO, the Genesis Mission is a “dedicated, coordinated national effort to unleash a new age of AI-accelerated innovation and discovery that can solve the most challenging problems of this century.”
Led by the Department of Energy (DOE), the initiative aims to build an integrated AI framework that would harness federal scientific datasets to accelerate breakthroughs in advanced manufacturing, biotechnology, critical materials, nuclear fission and fusion energy, quantum information science, and semiconductor development. The scope of the mission is comparable to that of the Manhattan Project.
Since the announcement, the DOE has listed “Predicting U.S. Water for Energy” among its 26 Genesis Mission Science and Technology Challenges. The project is also soliciting proposals in three water-related focus areas.
This framework provides a foothold for hydrology in the Genesis Mission, but it is scoped narrowly around water as a supply variable for energy production.
In reality, water is a crosscutting constraint that will help determine whether the mission’s priorities translate into deployable outcomes. The hydrology community now has a seat at the table, and if it moves first and positions water security as one of the “most challenging problems of this century,” the Genesis Mission can become the sandbox in which AI reshapes how the country measures, models, and manages water.
Making this happen will require that the DOE and the Office of Science and Technology Policy charter a hydrology workstream inside the Genesis Mission, with interagency delivery involving the U.S. Geological Survey (USGS), NOAA, the Bureau of Reclamation, the EPA, and partners at state, regional, and community levels. Here is what we think that workstream should look like:
A water-centric Genesis Mission architecture supports seven hydrological components that both feed into and receive decisions from the Genesis AI platform. Each component maps to a section of this article. Credit: Amobichukwu C. Amanambu. Click image for larger version.
While the existing challenges reflect some of these components, others will require coordinated effort from the hydrology community to bring into the Genesis Mission’s scope.
Build the Water Corpus Genesis Will Need
The Genesis Mission EO instructs the DOE to create an American Science and Security Platform to provide the public, scientists, agencies, and policymakers access to crucial scientific datasets.
The good news is that accessible water data systems already exist across several federal agencies and academic research centers. The USGS National Water Information System tracks real-time and historical water quality and use across the country. NASA’s Earth Science Data Systems Program provides open access to Earth science observations. NOAA’s National Water Center, the first federal facility dedicated to national water resource forecasting, operates the National Water Model, which continuously forecasts flows on 2.7 million stream reaches across the continental United States. The Catchment Attributes and Meteorology for Large-Sample Studies (CAMELS) dataset, currently hosted by the National Center for Atmospheric Research, provides data tailored for hydrological research on hundreds of river basins, and the Caravan framework pulls together multiple large-sample meteorological and hydrological datasets at a global scale.
What is missing is a unified, AI-ready repository that brings federal, state, and community data together.
What is missing is a unified, AI-ready repository that brings federal, state, and community data together. Building one is hard. Water data are fragmented, inconsistent, and often entirely absent. Consistent, reliable data for groundwater, withdrawals, reservoir operations, and water quality are especially difficult to obtain.
Local resistance to sharing data is real. In Texas, for example, landowners hold private property rights over groundwater and have opposed metering and reporting requirements imposed by groundwater conservation districts. In California, agricultural well owners fought metering mandates for years before the Sustainable Groundwater Management Act compelled local agencies to begin tracking withdrawals. Tribal nations face a different concern: Water data collected on Indigenous lands has been misrepresented in federal datasets that were modeled without accounting for Indian country, leading many nations to restrict access to their data as an exercise of sovereignty.
Practical steps toward building a unified AI-ready repository include tiered access and licensing for different stakeholders, clear provenance tracking for all data reported, financial and educational incentives for stakeholders for reporting, and targeted gap filling. Where measurements are missing, AI can fuse remote sensing with gauged records and operational logs—but only if the results carry honest uncertainty estimates tied to real decisions.
Get the corpus right, and it will outlive any single program name. It becomes infrastructure the country can lean on.
Develop Shared Hydrologic Foundation Models
The Genesis Mission EO directs the DOE to provide “domain-specific foundation models across the range of scientific domains covered.”
Hydrology has a head start. Long short-term memory (LSTM) networks are a key type of neural network designed to last thousands of time steps. Hydrology LSTMs trained on CAMELS data have already matched traditional conceptual models for daily streamflow discharge prediction. Open-source Neural Hydrology tools serve as baselines for regional runoff prediction. These predictions may serve as precursors to the foundation models the Genesis Mission envisions and building blocks from which they could be developed.
The process of scaling up these tools is not straightforward, however. A hydrologic investigation of snowmelt-driven streams in Colorado will not require the same spatiotemporal data as tile-drained fields in Iowa, for example. A hydrology-specific foundation model must take nuanced requirements into consideration and provide a clear path for managing and exploiting a variety of datasets.
Google’s Flood Hub shows what is possible: Its AI-enabled flood forecasts now cover more than 80 countries. However, Flood Hub’s core model code and trained weights remain proprietary, meaning researchers can use the forecasts but cannot rebuild or adapt the underlying models. Genesis, if well positioned, can fill that accessibility gap by producing foundation models for water that are reusable, reliable, and openly governed.
Build a National Water Digital Twin
The EO prescribes an integrated AI platform combining foundation models with simulation tools to stimulate AI-enabled innovations.
That architecture is exactly what a digital twin requires. Europe’s Destination Earth initiative is already building digital twins for weather extremes and nonstationary conditions on the Large Unified Modern Infrastructure (LUMI) supercomputer. The United Nations–led AI for Good initiative has prioritized water applications, warning that fragmented national efforts risk duplicating work.
If the United States aims for global strategic leadership in AI-accelerated science, water infrastructure cannot be an afterthought.
A water digital twin earns its keep when it makes the consequences of choices visible, in terms of flows, levels, temperatures, and risks to people and ecosystems.
Rather than starting from scratch, a water-centric Genesis Mission would unite existing federal models—the National Water Model, reservoir simulators, and groundwater codes—in a single digital twin. AI can become the thread that stitches them together, correcting biases and providing numerical solvers to enforce mass and energy balance.
What should this twin actually do? Help a dam operator decide whether to release water ahead of a storm. Tell planners where a new data center can draw cooling water without drying up a stream. Flag which coastal defenses will fail first under rising seas.
A water digital twin earns its keep when it makes the consequences of choices visible, in terms of flows, levels, temperatures, and risks to people and ecosystems.
Turn Basins into AI Test Beds
The Genesis Mission promotes AI-directed experimentation and directs the DOE to keep a record of robotic laboratories and production facilities in which such experimentation could be conducted. Hydrological field sites belong in that inventory. The National Ecological Observatory Network already operates 81 sites with standardized measurements of meteorology, surface water, groundwater, and biodiversity. The Critical Zone Collaborative Network instruments catchments to track water-soil-vegetation interactions over decades.
Formalizing these networks as AI test beds would link field observations back into the water digital twin so that experiments and models continually sharpen each other. Imagine mobile sensors steered by AI agents during a storm or aquifer recharge experiments designed by algorithms and verified in real time. That feedback loop is what separates a useful model from a decorative one.
Expand Water Challenges on the Genesis Mission List
The Exchange and What’s at Stake
Allowing water security to flow through the diverse components of the Genesis Mission would benefit both the policies championed by the mission itself and the hydrology community.
The Genesis Mission gets real-world, noisy test beds where AI proves value beyond benchmarks, a domain to stress test climate and infrastructure investments, and scientists trained in both AI and the stubborn realities of rivers, aquifers, and pipes.
Hydrology gets resources for shared data infrastructure, foundation models and instrumented basins no single lab can support, a seat when rules for AI and national scientific infrastructure are negotiated, and a chance to reset practices around openness, collaboration, and equity.
Earlier this year, the DOE released 26 Genesis Mission Science and Technology Challenges, and “Predicting U.S. Water for Energy” was among them. The accompanying funding call (DE-FOA-0003612) solicits proposals on cloud microphysics, coupled surface water–groundwater modeling, and seasonal to multiyear prediction, all framed around energy needs and flood resilience.
These inclusions are a significant win for a hydrology component to Genesis, but several urgent challenges sit outside their scope. Can AI close the gap between a flood forecast issued 12 hours out and the 48 hours emergency managers actually need? Can it map compound extremes, in which drought, heat, and infrastructure failure collide in the same week? Can it redesign monitoring networks so that coverage follows risk rather than where gauges happened to be installed a century ago? Integrating energy and water systems is equally urgent: Floods have caused 80% of major U.S. grid outages since 2000, while drought-driven water stress curtails cooling at thermoelectric plants and reduces hydropower output, exposing how deeply energy infrastructure depends on hydrologic extremes.
The water footprint of new AI infrastructure deserves a place on that list. A separate executive order (14318, “Accelerating Federal Permitting of Data Center Infrastructure”) is already fast-tracking expansion of data center construction, and a single hyperscale facility can consume 1 million to 5 million gallons of water daily. Emerging research shows how withdrawals at that scale can push streams below ecological thresholds during low flows.
Make Hydrology the Conscience of AI Governance
The EO directs the DOE to set data access rules and clarify policies for ownership, licensing, trade secret protections, and commercialization of products and tools associated with it.
Three principles should anchor such policies for AI use in water security.
First, Indigenous and community data rights must be embedded in every major AI water security effort, in line with the collective benefit, authority to control, responsibility, and ethics (CARE) principles for Indigenous data governance.
Second, AI’s own water footprint, through electricity generation and cooling, must be treated as a design constraint. Transparent reporting, stress-based siting, and efficiency targets will prevent hydrology in Genesis from being self-defeating.
Third, the DOE should define what failure looks like. Missing a flood crest portends loss of lives and livelihoods and breaches of treaties. Accountability standards must be measurable, and they must ask not just how accurate the forecast was on average, but who bore the cost when it was wrong.
A single executive order will not solve the country’s water security problems, and a single challenge topic will not either.
But the Genesis Mission has provided a seat at a table that did not exist 6 months ago. Whether the hydrology community treats it as a ceiling or a foundation depends on what happens next. Europe’s Destination Earth and the United Nations’ AI for Good water initiatives are already moving.
American hydrology now has a seat at the table. We should take it.
Kratzert, F., et al. (2019), Toward improved predictions in ungauged basins: Exploiting the power of machine learning, Water Resour. Res., 55, 11,344–11,354, https://doi.org/10.1029/2019WR026065.
Xiao, T., et al. (2025), Environmental impact and net-zero pathways for sustainable artificial intelligence servers in the USA, Nat. Sustainability, 8, 1,541–1,553, https://doi.org/10.1038/s41893-025-01681-y.
Zhang, L., et al. (2025), Foundation models as assistive tools in hydrometeorology: Opportunities, challenges, and perspectives, Water Resour. Res., 61, e2024WR039553, https://doi.org/10.1029/2024WR039553.
Author Information
Amobichukwu C. Amanambu (acamanambu@ua.edu), Department of Geography and the Environment, The University of Alabama, Tuscaloosa; and Jonathan Frame (jmframe@ua.edu), Department of Geological Sciences, The University of Alabama, Tuscaloosa
Citation: Amanambu, A. C., and J. Frame (2026), The Genesis Mission needs hydrology: Here’s how to incorporate it, Eos, 107, https://doi.org/10.1029/2026EO260131. Published on 28 April 2026.
This article does not represent the opinion of AGU, Eos, or any of its affiliates. It is solely the opinion of the author(s).